

Fog and Edge Computing
What is Fog and Edge Computing?
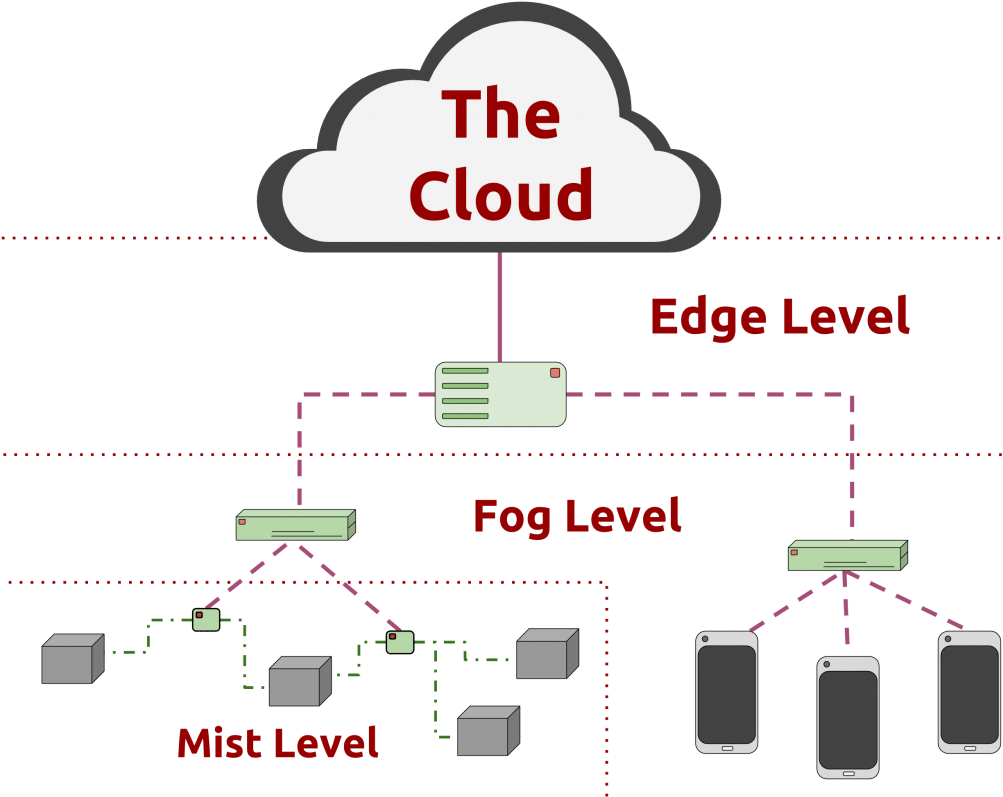 With the explosion of data, devices and interactions, cloud architecture on its own can't handle the influx of information. While the cloud gives us access to compute, storage and even connectivity that we can access easily and cost-effectively, these centralized resources can create delays and performance issues for devices and data that are far from a centralized public cloud or data center source.
With the explosion of data, devices and interactions, cloud architecture on its own can't handle the influx of information. While the cloud gives us access to compute, storage and even connectivity that we can access easily and cost-effectively, these centralized resources can create delays and performance issues for devices and data that are far from a centralized public cloud or data center source.
Edge computing—also known as just “edge”—brings processing close to the data source, and it does not need to be sent to a remote cloud or other centralized systems for processing. By eliminating the distance and time it takes to send data to centralized sources, we can improve the speed and performance of data transport, as well as devices and applications on the edge.
Fog computing is a standard that defines how edge computing should work, and it facilitates the operation of compute, storage and networking services between end devices and cloud computing data centers. Additionally, many use fog as a jumping-off point for edge computing.
So, when should you use the edge approach to computing? How does fog computing architecture fit in? Let's explore the value of this approach and standard to enterprise IT. Moreover, let's explore when edge computing and fog computing architecture make sense and when business processes might call for a centralized computing model.
Edge computing and fog computing defined
With edge, compute and storage systems reside at the edge as well, as close as possible to the component, device, application or human that produces the data being processed. The purpose is to remove processing latency, because the data needn't be sent from the edge of the network to a central processing system, then back to the edge.
The applications for edge make sense: Internet of Things-connected devices are a clear use for edge computing architecture. With remote sensors installed on a machine, component or device, they generate massive amounts of data. If that data is sent back across a long network link to be analyzed, logged and tracked, that takes much more time than if the data is processed at the edge, close to the source of the data.
Fog computing, a term created by Cisco, also refers to extending computing to the edge of the network. Cisco introduced its fog computing in January 2014 as a way to bring cloud computing capabilities to the edge of the network.
In essence, fog is the standard, and edge is the concept. Fog enables repeatable structure in the edge computing concept, so enterprises can push compute out of centralized systems or clouds for better and more scalable performance.
The edge in action
Obviously, edge and fog computing architecture is all about Internet of Things (IoT). Case studies that deal with remote sensors or devices are typically where edge computing and fog computing architectures manifest in the real world.
Consider Bombadier, an aerospace company, which in 2016 opted to use sensors in its aircraft. That move offered an opportunity to generate more revenue by giving Bombadier real-time performance data on its engines so it can address problems proactively without grounding its aircraft to fix an issue.
The ability to place processing at the edge next to a jet engine sensor has a real impact: One can instantly determine the status of the jet engine. This eliminates the need to send engine sensor data back to a central server, either on the plane or in the cloud to determine more pressing tactical issues, such as if the engine is overheating or burning too lean.
There are innovative things to do with that jet engine data that should not typically take place at the edge. Consider predictive analytics to determine whether the engine is about to fail based on sensor data gathered over the past month. Or, data analysis might involve root-cause analysis, such as determining why an engine has overheated rather than just indicating it's overheating. These strategic processes are better placed at centralized servers that can store and process petabytes of data, such as a public cloud.
Achieving success with edge and fog computing
The patterns of success when using edge computing and fog computing include the following:
- Target any process connected to an IoT device or sensor that can manage small amounts of data and small amounts of processing. The ability to deal with these processes at the edge will take care of about 90% of most required IoT-based processing, and the data and compute requirements are typically small, such as finding out whether a jet engine is overheating. An engine fitted with 5,000 sensors can generate up to 10 GB of data per second.
- Deal with more involved processing at a central server, such as deep data analysis or machine learning systems. Set up tiers of processing to centralize where the processing that requires much more data storage and compute cycles exists, and put the tactical processing that does not require as much horsepower at the edge.
Encountering failure with edge and fog computing
Of course, there are patterns of failure, as well:
- If you place too much at the edge, it's easy to overwhelm the smaller processor and storage platforms that exist there. In some cases, storage could be limited to a few gigabytes and processing using a single CPU. Power and size restrictions are really what set the limits.
- Another pattern is failure to integrate security from concept to production. Security is systemic to both edge and fog computing architectures and centralized processing. Security needs to span both and use mechanisms such as identity and access management. Encryption is not a nice-to-have, but rather a requirement for device safety. Imagine if a jet engine could be hacked in flight.
Fog and edge could create a tipping point, of sorts. Network latency limited IoT's full evolution and maturity given the limited processing that can occur at sensors. Placing a micro-platform at the IoT device, as well as providing tools and approaches to leverage this platform, will likely expand the capabilities of IoT systems and provide more use cases for IoT in general.
Fog and edge are enabling technologies and standards that give IoT users and technology providers with more options. Removing the limits of centralized cloud servers means IoT is much more distributed and flexible in the services providers can offer.
The first step is to understand what edge and fog are, how they can be best exploited within your own problem domain, and then face real business problems. Consider the number of ways edge and fog computing can make consumers' and workers' lives better. The value is limitless.
Select the language of your preference